Start 树 哈夫曼树(最优二叉树)
哈夫曼算法:
构造 n 棵二叉树森林,每一个都是带权值的根节点。
选择权值最小的两棵树作为左右子树,其根节点的权值为左右子树权值之和。
删除这两棵树,将新的树加入森林。
重复操作到只剩下一棵树为止。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 #include <stdio.h> #include <stdlib.h> #include <string.h> typedef double DataType; typedef struct HTNode { DataType weight; int parent; int lc, rc; }*HuffmanTree; typedef char **HuffmanCode; void Select (HuffmanTree& HT, int n, int & s1, int & s2) int min; for (int i = 1 ; i <= n; i++) { if (HT[i].parent == 0 ) { min = i; break ; } } for (int i = min + 1 ; i <= n; i++) { if (HT[i].parent == 0 && HT[i].weight < HT[min].weight) min = i; } s1 = min; for (int i = 1 ; i <= n; i++) { if (HT[i].parent == 0 && i != s1) { min = i; break ; } } for (int i = min + 1 ; i <= n; i++) { if (HT[i].parent == 0 && HT[i].weight < HT[min].weight&&i != s1) min = i; } s2 = min; } void CreateHuff (HuffmanTree& HT, DataType* w, int n) int m = 2 * n - 1 ; HT = (HuffmanTree)calloc (m + 1 , sizeof (HTNode)); for (int i = 1 ; i <= n; i++) { HT[i].weight = w[i - 1 ]; } for (int i = n + 1 ; i <= m; i++) { int s1, s2; Select (HT, i - 1 , s1, s2); HT[i].weight = HT[s1].weight + HT[s2].weight; HT[s1].parent = i; HT[s2].parent = i; HT[i].lc = s1; HT[i].rc = s2; } printf ("哈夫曼树为:>\n" ); printf ("下标 权值 父结点 左孩子 右孩子\n" ); printf ("0 \n" ); for (int i = 1 ; i <= m; i++) { printf ("%-4d %-6.2lf %-6d %-6d %-6d\n" , i, HT[i].weight, HT[i].parent, HT[i].lc, HT[i].rc); } printf ("\n" ); } void HuffCoding (HuffmanTree& HT, HuffmanCode& HC, int n) HC = (HuffmanCode)malloc (sizeof (char *)*(n + 1 )); char * code = (char *)malloc (sizeof (char )*n); code[n - 1 ] = '\0' ; for (int i = 1 ; i <= n; i++) { int start = n - 1 ; int c = i; int p = HT[c].parent; while (p) { if (HT[p].lc == c) code[--start] = '0' ; else code[--start] = '1' ; c = p; p = HT[c].parent; } HC[i] = (char *)malloc (sizeof (char )*(n - start)); strcpy (HC[i], &code[start]); } free (code); } int main () int n = 0 ; printf ("请输入数据个数:>" ); scanf ("%d" , &n); DataType* w = (DataType*)malloc (sizeof (DataType)*n); if (w == NULL ) { printf ("malloc fail\n" ); exit (-1 ); } printf ("请输入数据:>" ); for (int i = 0 ; i < n; i++) { scanf ("%lf" , &w[i]); } HuffmanTree HT; CreateHuff (HT, w, n); HuffmanCode HC; HuffCoding (HT, HC, n); for (int i = 1 ; i <= n; i++) { printf ("数据%.2lf的编码为:%s\n" , HT[i].weight, HC[i]); } free (w); return 0 ; }
二叉树:求树的高度
递归
1 2 3 4 5 6 7 8 9 int GetHeight (BinTree BT) { if (!BT) return 0 ; return max(GetHeight(BT->Left),GetHeight(BT->Right))+1 ; } int max (int a,int b) {return a > b ? a : b;}
使用队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 int GetHeight ( BinTree BT ) { if (BT==NULL )return 0 ; BinTree arr[100 ]; BinTree tmpFront; int front=0 ,rear=0 ; int h=0 ; arr[rear++]=BT; int count=1 ; int nextCount=1 ; while (front!=rear){ h++; count=nextCount; nextCount=0 ; while (count--){ tmpFront=arr[front++]; if (tmpFront->Left){ arr[rear++]=tmpFront->Left; nextCount++; } if (tmpFront->Right){ arr[rear++]=tmpFront->Right; nextCount++; } } } return h; }
二叉树:顺序存储 存储按照完全二叉树来(遇到空节点则 赋值 isEmpty 为 true)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #define MaxSize 100 struct TreeNode { ElemType value; bool isEmpty; } int main () { TreeNode t[MaxSize]; for (int i=0 ; i<MaxSize; i++){ t[i].isEmpty = true ; } }
二叉树的创建 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void creat (BiTree *T) { char ch; scanf ("%c" ,&ch); if (ch=='#' ) *T=NULL ; else { *T=(BiTree)malloc (sizeof (BiTNode)); (*T)->data=ch; creat(&(*T)->lchild); creat(&(*T)->rchild); } }
二叉树的遍历
1 2 3 4 5 6 7 8 9 10 11 12 int PreOrder (BiTree T) { if (T!=NULL ){ visit(T); PreOrder(T->lchild); PreOrder(T->rchild); } else { return 0 ; } return 1 ; }
二叉树:中序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 int ShowZhongXu (BitTree T) { if (T==NULL ) { return 0 ; } else { ShowZhongXu(T->lchild); printf ("%d " ,T->data); ShowZhongXu(T->rchild); } return 1 ; }
二叉树:后序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 int ShowZhongXu (BitTree T) { if (T==NULL ) { return 0 ; } else { ShowZhongXu(T->lchild); ShowZhongXu(T->rchild); printf ("%d " ,T->data); } return 1 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void LevelOrder (BiTree T) { LinkQueue Q; InitQueue (Q); BiTree p; EnQueue(Q,T); while (!isEmpty(Q)){ DeQueue(Q,p); visit(p); if (p->lchild != NULL ) EnQueue(Q,p->lchild); if (p->rchild != NULL ) EnQueue(Q,p->rchild); } }
二叉树交换左右孩子 1 2 3 4 5 6 7 8 9 10 11 12 void swap (BiTree T) { if (T!=NULL ) { BiTNode *m=T->lchild; T->lchild=T->rchild; T->rchild=m; swap(T->lchild); swap(T->rchild); } }
求二叉树高度(深度) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int Depth ( BiTree T ) { int countl =0 ; int countr =0 ; int max; if (T==NULL ){ return 0 ; } else { countl=Depth( T->lchild ); countr=Depth( T->rchild ); max=countl>countr? countl:countr; return max+1 ; } }
线索二叉树
将空的指针域用以指向前驱后继节点。
遵循:
ltag==0,指向左孩子;ltag==1,指向前驱结点
rtag==0,指向右孩子;rtag==1,指向后继结点
1. 二叉树的线索化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 void inOrderThreadTree (Node* node) { if (node == NULL ) { return ; } inOrderThreadTree(node->left_node); if (node->left_node == NULL ) { node->left_type = 1 ; node->left_node = pre; } if (pre !=NULL && pre->right_node == NULL ) { pre->right_node = node; pre->right_type = 1 ; } pre = node; inOrderThreadTree(node->right_node); }
中序遍历线索二叉树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void inOrderTraverse (Node* root) { if (root == NULL ) { return ; } Node* temp = root; while (temp != NULL && temp->left_type == 0 ) { temp = temp->left_node; } while (temp != NULL ) { temp = temp->right_node; } }
二叉搜索树 线索二叉树操作集合
结构体
1 2 3 4 5 6 7 typedef struct TNode *Position ;typedef Position BinTree;struct TNode { ElementType Data; BinTree Left; BinTree Right; };
主函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <stdio.h> #include <stdlib.h> typedef int ElementType;typedef struct TNode *Position ;typedef Position BinTree;struct TNode { ElementType Data; BinTree Left; BinTree Right; }; void PreorderTraversal ( BinTree BT ) ; void InorderTraversal ( BinTree BT ) ; BinTree Insert ( BinTree BST, ElementType X ) ; BinTree Delete ( BinTree BST, ElementType X ) ; Position Find ( BinTree BST, ElementType X ) ; Position FindMin ( BinTree BST ) ; Position FindMax ( BinTree BST ) ; int main () { BinTree BST, MinP, MaxP, Tmp; ElementType X; int N, i; BST = NULL ; scanf ("%d" , &N); for ( i=0 ; i<N; i++ ) { scanf ("%d" , &X); BST = Insert(BST, X); } printf ("Preorder:" ); PreorderTraversal(BST); printf ("\n" ); MinP = FindMin(BST); MaxP = FindMax(BST); scanf ("%d" , &N); for ( i=0 ; i<N; i++ ) { scanf ("%d" , &X); Tmp = Find(BST, X); if (Tmp == NULL ) printf ("%d is not found\n" , X); else { printf ("%d is found\n" , Tmp->Data); if (Tmp==MinP) printf ("%d is the smallest key\n" , Tmp->Data); if (Tmp==MaxP) printf ("%d is the largest key\n" , Tmp->Data); } } scanf ("%d" , &N); for ( i=0 ; i<N; i++ ) { scanf ("%d" , &X); BST = Delete(BST, X); } printf ("Inorder:" ); InorderTraversal(BST); printf ("\n" ); return 0 ; }
操作集合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 BinTree Insert ( BinTree BST, ElementType X ) { if (BST==NULL ) { BST = (BinTree)malloc (sizeof (BinTree)); BST ->Data = X; BST ->Left = BST ->Right = NULL ; }else { if (X < BST ->Data ) { BST ->Left = Insert(BST ->Left, X); }else if (X > BST ->Data ) { BST ->Right = Insert(BST ->Right, X); } } return BST; } BinTree Delete ( BinTree BST, ElementType X ) { BinTree Tmp; if (BST==NULL ) printf ("Not Found\n" ); else { if ( X < BST->Data) BST ->Left = Delete(BST->Left, X); else if (X > BST->Data ) BST ->Right = Delete(BST->Right , X); else { if (BST->Left && BST->Right) { Tmp=FindMin(BST->Right); BST->Data = Tmp ->Data; BST->Right=Delete(BST->Right,BST->Data); }else { Tmp = BST; if (!BST->Left) BST = BST->Right; else if (!BST->Right) BST = BST->Left; free (Tmp); } } } return BST; } Position Find ( BinTree BST, ElementType X ) { if (BST==NULL ) return NULL ; if (BST->Data==X) return BST; if (X>BST->Data) return Find(BST->Right,X); if (X<BST->Data) return Find(BST->Left,X); } Position FindMin ( BinTree BST ) { if (BST){ while (BST->Left){ BST=BST->Left; } } return BST; } Position FindMax ( BinTree BST ) { if (BST){ while (BST->Right){ BST=BST->Right; } } return BST; }
图 并查集 主要用于解决一些元素分组 的问题。也可以用来判断图的连通性,它管理一系列不相交的集合 ,并支持两种操作:
合并 (Union):把两个不相交的集合合并为一个集合。查询 (Find):查询两个元素是否在同一个集合中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 int find (int x) { if (father[x]!=x) father[x]=find(father[x]); return father[x]; } int find (int x) { int a; a=x; while (x!=father[x])x=father[x]; while (a!=father[a]){ int z=a; a=father[a]; father[z]=x; } return x; } void Union (int a,int b) { int fx=find(a); int fy=find(b); father[fx]=fy; } int judgeConnect () { int i,k=0 ; for (i=1 ;i<=vertex;i++) if (father[i]==i) k++; if (k==1 ) return 1 ; else return 0 ; }
AOE图
concept:
1、最早发生 时间:从前往后,前驱结点到当前结点所需时间,取最大值 ;
2、最迟发生 时间:从后往前,后继结点的最迟时间减去边权的值,取最小值 ;
结束节点的最早发生时间和最迟发生时间相同。
3、关键路径:最早发生时间和最迟发生时间相同的结点叫做关键路径上的结点;
4、最早开始 时间:等于当前边起始节点的最早发生时间;
5、最晚开始 时间:等于当前便指向结点的最迟时间减去当前边的权值;
6、最早完工 时间:等于当前边指向结点的最早发生时间;
7、最晚完工 时间:等于当前边指向结点的最迟发生时间;
图的链式存储结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #include <stdio.h> #include <stdlib.h> #define MVNum 100 typedef struct ArcNode { int adjvex; struct ArcNode * nextarc ; }ArcNode; typedef struct VNode { char data; ArcNode * firstarc; }VNode, AdjList[MVNum]; typedef struct { AdjList vertices; int vexnum, arcnum; }ALGraph; void CreatMGraph (ALGraph *G) ;void printGraph (ALGraph G) ;int main () { ALGraph G; CreatMGraph(&G); printGraph(G); return 0 ; } void CreatMGraph (ALGraph *G) { int i,j,k; ArcNode *s; scanf ("%d%d" ,&G->vexnum,&G->arcnum); getchar(); for (i=0 ;i<G->vexnum;i++) scanf ("%c" ,&G->vertices[i].data); for (i=0 ;i<G->vexnum;i++) G->vertices[i].firstarc=NULL ; for (k=0 ;k<G->arcnum;k++) { scanf ("%d%d" ,&i,&j); s=(ArcNode*)malloc (sizeof (ArcNode)); s->adjvex=j; s->nextarc=G->vertices[i].firstarc; G->vertices[i].firstarc=s; s=(ArcNode*)malloc (sizeof (ArcNode)); s->adjvex=i; s->nextarc=G->vertices[j].firstarc;; G->vertices[j].firstarc=s; } } void printGraph (ALGraph G) { int i,j; ArcNode *p; for (i=0 ;i<G.vexnum;i++) { printf ("%c:" ,G.vertices[i].data); for (p=G.vertices[i].firstarc;p;p=p->nextarc) printf (" %c" ,G.vertices[p->adjvex].data); printf ("\n" ); } }
查找(搜索) 折半搜索
因为折半查找需要方便地定位查找区域,所以它要求线性表必须具有随机存取的特性。因此,该查找法仅适合于顺序存储结构,不适合于链式存储结构,且要求元素按关键字有序排列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <stdio.h> int BinSearch (int array [], int x, int n) ;int main () { int arr[10 ]; int num; for (int i=0 ;i<10 ;i++) { arr[i]=i; } int re=BinSearch(arr,9 ,10 ); printf ("下标:%d\n" ,re); return 0 ; } int BinSearch (int array [], int x, int n) { int low = 0 , high = n-1 , mid; int num=0 ; while (low <= high) { num++; mid = low + (high - low) / 2 ; printf ("%d\n" ,mid); if (x > array [mid]) low = mid + 1 ; else if (x < array [mid]) high = mid - 1 ; else { printf ("次数:%d\n" ,num); return mid; } } return -1 ; }
插值查找
类似于折半搜索,只是mid的计算方法不一样
比较元素的下标:
Mid = Begin + ( (End - Begin) / (A[End] - A[Begin]) ) * (X - A[Begin])
式子中,各部分的含义分别是:
Mid:计算得出的元素的位置;
End:搜索区域内最后一个元素所在的位置;
Begin:搜索区域内第一个元素所在的位置;
X:要查找的目标元素;
A[]:表示整个待搜索序列
C语言实现过程
递归算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <stdio.h> int interpolation_search (int * arr, int begin, int end, int ele) { int mid = 0 ; if (begin > end) { return -1 ; } if (begin == end) { if (ele == arr[begin]) { return begin; } return -1 ; } mid = begin + ((end - begin) / (arr[end] - arr[begin]) * (ele - arr[begin])); if (ele == arr[mid]) { return mid; } if (ele < arr[mid]) { return interpolation_search(arr, begin, mid - 1 , ele); } else { return interpolation_search(arr, mid + 1 , end, ele); } } int main () { int arr[10 ] = { 1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ,10 }; int pos = interpolation_search(arr, 0 , 9 , 2 ); if (pos != -1 ) { printf ("%d" , interpolation_search(arr, 0 , 9 , 2 )); } else { printf ("查找失败" ); } return 0 ; }
二叉排序树
若左子树非空,则左子树上所有结点的值均小于根结点的值。
若右子树非空,则右子树上所有结点的值均大于根结点的值。
左、右子树也分别是一棵二叉排序树。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 typedef struct BiTNode { int data; struct BiTNode *lchild , *rchild ; } BiTNode, *Bitree; bool SearchBST (BiTree T, int key, BiTree f, BiTree *p) { if (!T){ *p = f; return FALSE; }else if (key == T->data){ *p = T; return TRUE; }else if (key < T->data){ return SearchBST(T->lchild, key, T, p); }else { return SearchBST(T->rchild, key, T, p); } } bool InsertBST (BiTree *T, int key) { BiTree p, s; if (!SearchBST(*T, key, NULL , &p)){ s = (BiTree)malloc (sizeof (BiTNode)); s->data = key; s->lchild = s->rchild = NULL ; if (!p){ *T = s; }else if (key < p->data){ p->lchild = s; }else { p->rchild = s; } return TRUE; }else { return FALSE; } } int i;int a[10 ] = {62 , 88 , 58 , 47 , 35 , 73 , 51 , 99 , 37 , 93 };BiTree T = NULL ; for (i = 0 ; i<10 ; i++){ InsertBST(&T, a[i]); } bool DeleteBST (BiTree *T, int key) { if (!T){ return FALSE; }else { if (key == T->data){ return Delete(T); }else if (key < T -> data){ return DeleteBST(T -> lchild, key); }else { return DeleteBST(T -> rchild, key); } } }
哈希表(散列表)
散列表是根据关键字而直接进行访问的数据结构。也就是说,散列表建立了关键字和存储地址之间的一种直接映射关系。
这种对应关系称为散列函数,又称为哈希(Hash) 函数。按这个思想,采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。那么关键字对应的记录存储位置我们称为散列地址。
散列函数的构造方法
直接定址法
直接取关键字的某个线性函数值为散列地址,散列函数为:
数字分析法
分析数字关键字在各位上的变化情况,取比较随机的位作为散列地址。
平方取中法
平方取中法比较适合于不知道关键字的分布,而位数又不是很大的情况。
字面意思:平方之后取中间的数字作为散列地址
除留余数法
散列函数:
h(key) = key % 17
随机数法
$$
处理散列冲突 开放地址法(闭散列表)和链地址法(开散列表法)
线性探测法
从冲突的的下一个位置起,依次寻找空的散列地址
公式:
二次(平方)探测法
公式
拉链法
将所有关键字为同义词的记录存储在一个单链表中,我们称这种表为同义词子表,在散列表中只存储所有同义词子表的头指针。
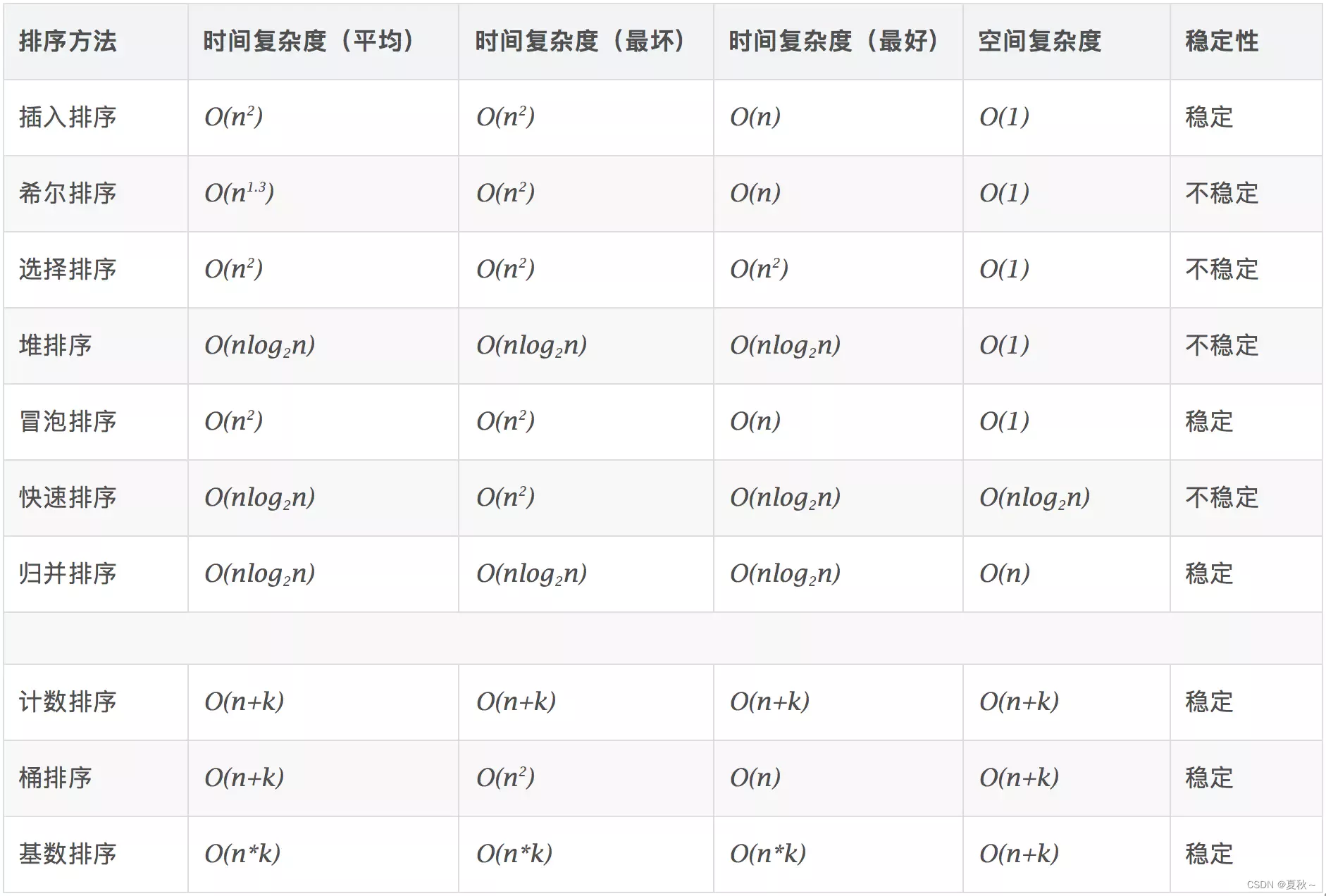
排序 插入排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 void InsertSort (int * arr, int n) { for (int i = 0 ; i < n - 1 ; ++i) { int end = i; int tem = arr[end + 1 ]; while (end >= 0 ) { if (tem < arr[end]) { arr[end + 1 ] = arr[end]; end--; } else { break ; } } arr[end + 1 ] = tem; } }
时间复杂度:
最坏(逆序):O(n^2)
最好(升序):O(n)
空间复杂度:O(1)
希尔排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void ShellSort (int * arr, int n) { int gap = n; while (gap>1 ) { gap = gap / 2 ; for (int i = 0 ; i < n - gap; ++i) { int end = i; int tem = arr[end + gap]; while (end >= 0 ) { if (tem < arr[end]) { arr[end + gap] = arr[end]; end -= gap; } else { break ; } } arr[end + gap] = tem; } } }
时间复杂度(平均):O(N^1.3)
选择排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 void swap (int * a, int * b) { int tem = *a; *a = *b; *b = tem; } void SelectSort (int * arr, int n) { int begin = 0 , end = n - 1 ; while (begin < end) { int maxi = begin; int mini = begin; for (int i = begin; i <= end; ++i) { if (arr[i] < arr[mini]) { mini = i; } if (arr[i] > arr[maxi]) { maxi = i; } } swap(&arr[mini], &arr[begin]); if (begin == maxi) { maxi = mini; } swap(&arr[maxi], &arr[end]); ++begin; --end; } } c
时间复杂度:
空间复杂度:O(1)
冒泡排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 void BubbleSort (int * arr, int n) { int end = n; while (end) { int flag = 0 ; for (int i = 1 ; i < end; ++i) { if (arr[i - 1 ] > arr[i]) { int tem = arr[i]; arr[i] = arr[i - 1 ]; arr[i - 1 ] = tem; flag = 1 ; } } if (flag == 0 ) { break ; } --end; } }
时间复杂度:
空间复杂度:O(1)
堆排序
堆的分类:
大根堆:每个节点的值大于或等于左右孩子节点的值
小根堆:每个节点的值小于或等于左右孩子节点的值
步骤:
构造大根堆
顶端与末尾值交换
将剩下的n-1个数造次构造为大根堆,重复上述操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 void HeapAdjust (int * arr, int start, int end) { int tmp = arr[start]; for (int i = 2 * start + 1 ; i <= end; i = i * 2 + 1 ) { if (i < end&& arr[i] < arr[i + 1 ]) { i++; } if (arr[i] > tmp) { arr[start] = arr[i]; start = i; } else { break ; } } arr[start] = tmp; } void HeapSort (int * arr, int len) { for (int i=(len-1 -1 )/2 ;i>=0 ;i--) { HeapAdjust(arr, i, len - 1 ); } int tmp; for (int i = 0 ; i < len - 1 ; i++) { tmp = arr[0 ]; arr[0 ] = arr[len - 1 -i]; arr[len - 1 - i] = tmp; HeapAdjust(arr, 0 , len - 1 -i- 1 ); } } int main () { int arr[] = { 9 ,5 ,6 ,3 ,5 ,3 ,1 ,0 ,96 ,66 }; HeapSort(arr, sizeof (arr) / sizeof (arr[0 ])); printf ("排序后为:" ); for (int i = 0 ; i < sizeof (arr) / sizeof (arr[0 ]); i++) { printf ("%d " , arr[i]); } return 0 ; }
时间复杂度:时间复杂度为O(nlogn)
空间复杂度:O(1)
快速排序(挖坑法) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 int PartSort (int * arr, int left, int right) { int key = arr[left]; int hole = left; while (left < right) { while (left < right && arr[right] >= key) { right--; } arr[hole] = arr[right]; hole = right; while (left < right && arr[left] <= key) { left++; } arr[hole] = arr[left]; hole = left; } arr[hole] = key; return hole; }
快速排序(库函数直接调用法) 函数原型
1 void qsort (void * base,size_t num,size_t width,int (__cdecl*compare)(const void *,const void *)) ;
案例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <stdio.h> #include <stdlib.h> int cmp (const void *a,const void *b) { return *(int *)a-*(int *)b; } int main () { int n,i; scanf ("%d" ,&n); int time[n]; for (i=0 ; i<n; i++) { scanf ("%d" ,&time[i]); } qsort(time,n,sizeof (int ),cmp); for (i=0 ;i<n;i++){ printf ("%d " ,time[i]); } return 0 ; }
归并排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 void Merge (int sourceArr[],int tempArr[], int startIndex, int midIndex, int endIndex) { int i = startIndex, j=midIndex+1 , k = startIndex; while (i!=midIndex+1 && j!=endIndex+1 ) { if (sourceArr[i] > sourceArr[j]) tempArr[k++] = sourceArr[j++]; else tempArr[k++] = sourceArr[i++]; } while (i != midIndex+1 ) tempArr[k++] = sourceArr[i++]; while (j != endIndex+1 ) tempArr[k++] = sourceArr[j++]; for (i=startIndex; i<=endIndex; i++) sourceArr[i] = tempArr[i]; } void MergeSort (int sourceArr[], int tempArr[], int startIndex, int endIndex) { int midIndex; if (startIndex < endIndex) { midIndex = startIndex + (endIndex-startIndex) / 2 ; MergeSort(sourceArr, tempArr, startIndex, midIndex); MergeSort(sourceArr, tempArr, midIndex+1 , endIndex); Merge(sourceArr, tempArr, startIndex, midIndex, endIndex); } } int main (int argc, char * argv[]) { int a[8 ] = {50 , 10 , 20 , 30 , 70 , 40 , 80 , 60 }; int i, b[8 ]; MergeSort(a, b, 0 , 7 ); for (i=0 ; i<8 ; i++) printf ("%d " , a[i]); printf ("\n" ); return 0 ; }
时间复杂度:O(nlogn)。
空间复杂度:O(N),归并排序需要一个与原数组相同长度的数组做辅助来排序。
基数排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 #include <math.h> void testBS () { inta[] = {2 , 343 , 342 , 1 , 123 , 43 , 4343 , 433 , 687 , 654 , 3 }; int *a_p = a; intsize = sizeof (a) / sizeof (int ); bucketSort3(a_p, size); inti; for (i = 0 ; i < size; i++) { printf ("%d\n" , a[i]); } intt; scanf ("%d" , t); } void bucketSort3 (int *p, intn) { intmaxNum = findMaxNum(p, n); intloopTimes = getLoopTimes(maxNum); inti; for (i = 1 ; i <= loopTimes; i++) { sort2(p, n, i); } } int getLoopTimes (intnum) { intcount = 1 ; inttemp = num / 10 ; while (temp != 0 ) { count++; temp = temp / 10 ; } returncount; } int findMaxNum (int *p, intn) { inti; intmax = 0 ; for (i = 0 ; i < n; i++) { if (*(p + i) > max) { max = *(p + i); } } returnmax; } void sort2 (int *p, intn, intloop) { intbuckets[10 ][20 ] = {}; inttempNum = (int )pow (10 , loop - 1 ); inti, j; for (i = 0 ; i < n; i++) { introw_index = (*(p + i) / tempNum) % 10 ; for (j = 0 ; j < 20 ; j++) { if (buckets[row_index][j] == NULL ) { buckets[row_index][j] = *(p + i); break ; } } } intk = 0 ; for (i = 0 ; i < 10 ; i++) { for (j = 0 ; j < 20 ; j++) { if (buckets[i][j] != NULL ) { *(p + k) = buckets[i][j]; buckets[i][j] = NULL ; k++; } } } }
应试 概述作业
数据在计算机内存中的表示是指() 。数据的存储结构
数据结构形式地定义为(K,R),其中K是()的有限集合,R是K上的关系上的有限集合。数据元素
数据结构形式地定义为(D,S),其中D是数据元素的有限集合,S是D上的()的有限集合。关系
一个广义表的表尾总是一个( )。广义表
线性表
对于线性表的各种操作,考虑:
length与MaxSize的关系
length是否为零
输入的参数是否符合规则(大于或小于零,是否为空)
栈
对于栈的各种操作,考虑:
栈空或栈满的情况
输入的参数是否符合规则(大于或小于零,是否为空)
从左往右开始扫描中缀表达式。
队列
对于队列的各种操作,考虑:
队列空和满的情况
输入的参数是否符合规则(大于或小于零,是否为空)
图
用邻接矩阵表示有N个结点E条边的图时,深度优先遍历算法的时间复杂度是:C.O(N2)
栈与队列
下列关于栈的叙述中,错误的是:
采用非递归方式重写递归程序时必须使用栈 函数调用时,系统要用栈保存必要的信息
只要确定了入栈次序,即可确定出栈次序 栈是一种受限的线性表,允许在其两端进行操作
最不适合用作栈的链表是()。
A.只有表头指针没有表尾指针的循环双链表
B.只有表尾指针没有表头指针的循环双链表
C.只有表尾指针没有表头指针的循环单链表
D.只有表头指针没有表尾指针的循环单链表
下列关于栈的叙述中,错误的是:
采用非递归方式重写递归程序时必须使用栈
函数调用时,系统要用栈保存必要的信息
只要确定了入栈次序,即可确定出栈次序
栈是一种受限的线性表,允许在其两端进行操作
A.仅 1
B.仅 1、2、3
**C.**仅 1、3、4
D.仅 2、3、4
循环队列的引入是为了( )。克服假溢出
树
树的后序遍历与其对应的二叉树的哪种遍历相同?中序
森林的中序遍历与对应二叉树的什么遍历序列相同?中序
排序
有组记录的排序码为{ 46,79,56,38,40,84 },则利用堆排序的方法建立的初始堆为:
84,79,56,38,40,46
下面四种排序算法中,稳定的算法是:归并排序
快速排序下列排序算法中,时间复杂度不受数据初始状态影响,恒为O(NlogN)的是:
堆排序
对N个记录进行快速排序,在最坏的情况下,其时间复杂度是:
O(N2)
下列关键码序列中,属于堆的是( )。
(15,30,22,93,52,71)